教程 - 从亚马逊 S3 Bucket 加载
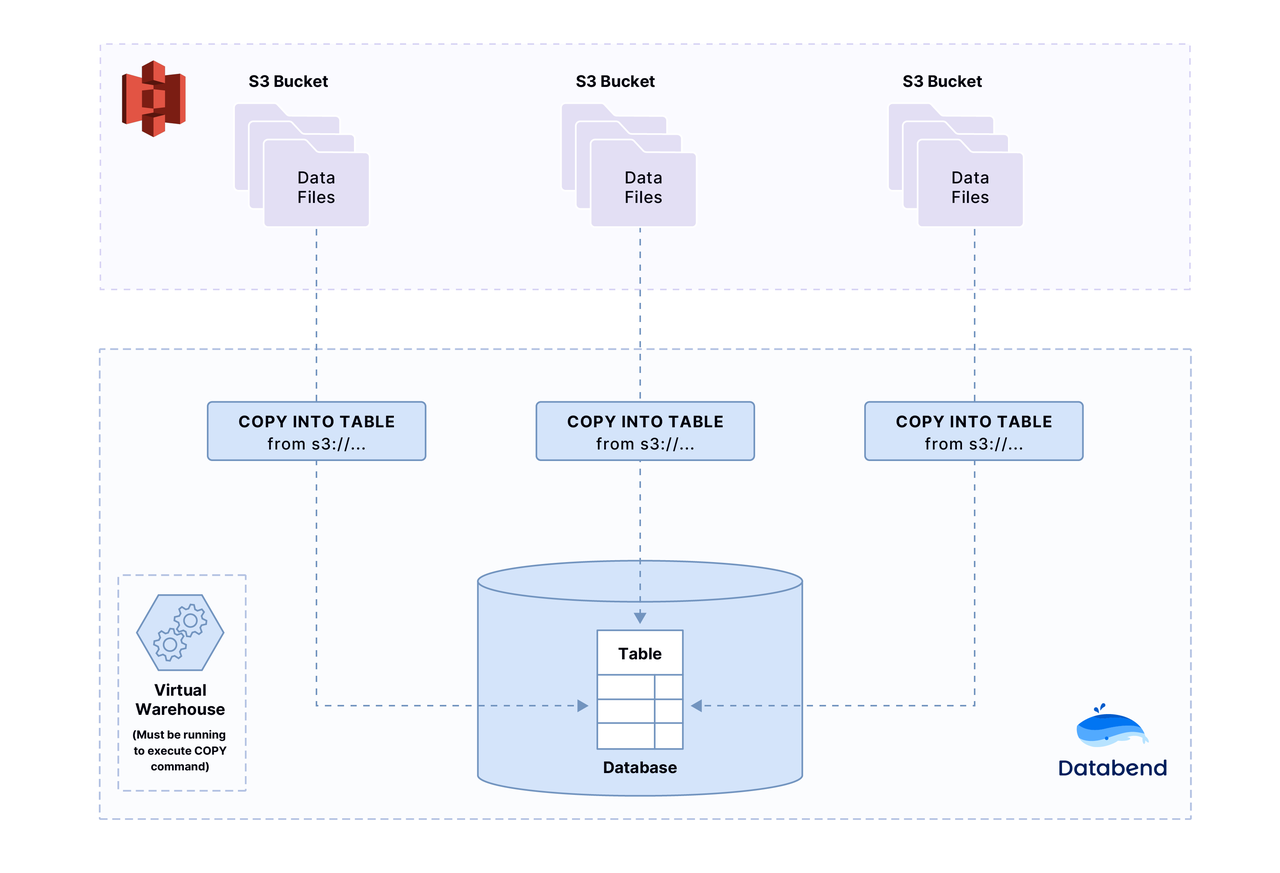
在本教程中,您将会将一个样本文件上传到您的 亚马逊 S3 Bucket,然后用 COPY INTO 命令将文件中的数据加载到 Databend。
第1步: 下载数据文件
下载示例数据文件(选择 CSV 或 Parquet),文件包含两项记录:
Transaction Processing,Jim Gray,1992
Readings in Database Systems,Michael Stonebraker,2004
- CSV
- Parquet
下载 books.csv
第2步: 创建一个亚马逊 S3 Bucket
如果您不知道如何创建亚马逊 S3 Bucket,请参阅 创建 Amazon S3 Bucket。
第3步: 将示例数据文件添加到亚马逊 S3 Bucket
上传 books.csv 或 books.parquet 文件到 Bucket。
如果您不知道如何将文件上传到亚马逊 S3 bucket,请参阅 上传文件到亚马逊 S3 Bucket。
第4步: 创建数据库和表
mysql -h127.0.0.1 -uroot -P3307
CREATE DATABASE book_db;
USE book_db;
CREATE TABLE books
(
title VARCHAR,
author VARCHAR,
date VARCHAR
);
数据库和表格已经成功创建。 您已经上传了 books.csv 或 books.parquet 文件到您的 Bucket。 若要使用 COPY INTO 加载数据,您将需要以下信息:
- S3 URI (s3://bucket/to/path/),例如: s3://databend-bohu/data/。
- 您的亚马逊帐户的访问密钥,例如:
- 访问密钥 ID: 您的访问密钥 ID
- 秘密访问密钥: 您的秘密访问密钥
- 安全令牌 (可选): 亚马逊临时访问令牌
第5步:将数据复制到目标表
执行以下语句(占位符换成您的URI 和密钥信息):
- CSV
- Parquet
COPY INTO books
FROM 's3://databend-bohu/data/'
credentials=(aws_key_id='<your-access-key-id>' aws_secret_key='<your-secret-access-key>' [aws_token='<your-aws-temporary-access-token>'])
pattern ='.*[.]csv'
file_format = (type = 'CSV' field_delimiter = ',' record_delimiter = '\n' skip_header = 0);
COPY INTO books
FROM 's3://databend-bohu/data/'
credentials=(aws_key_id='<your-access-key-id>' aws_secret_key='<your-secret-access-key>')
pattern ='.*[.]parquet'
file_format = (type = 'Parquet');
tip
如果文件太大,您可能想要尝试检查文件是否可以解析,我们可以使用 SIZE_LIMIT:
COPY INTO books
FROM 's3://databend-bohu/data/'
credentials=(aws_key_id='<your-access-key-id>' aws_secret_key='<your-secret-access-key>')
pattern ='.*[.]csv'
file_format = (type = 'CSV' field_delimiter = ',' record_delimiter = '\n' skip_header = 0)
size_limit = 1; -- only load 1 rows
第6步: 验证加载的数据
现在,让我们检查一下数据是否已经成功加载:
SELECT * FROM books;
+------------------------------+----------------------+-------+
| title | author | date |
+------------------------------+----------------------+-------+
| Transaction Processing | Jim Gray | 1992 |
| Readings in Database Systems | Michael Stonebraker | 2004 |
+------------------------------+----------------------+-------+