
Many optimizations are usually required for big data analytics to "reduce the distance to data." For example, using the Bloom Filter Index, queries can be filtered to determine whether data should be fetched from backend storage:
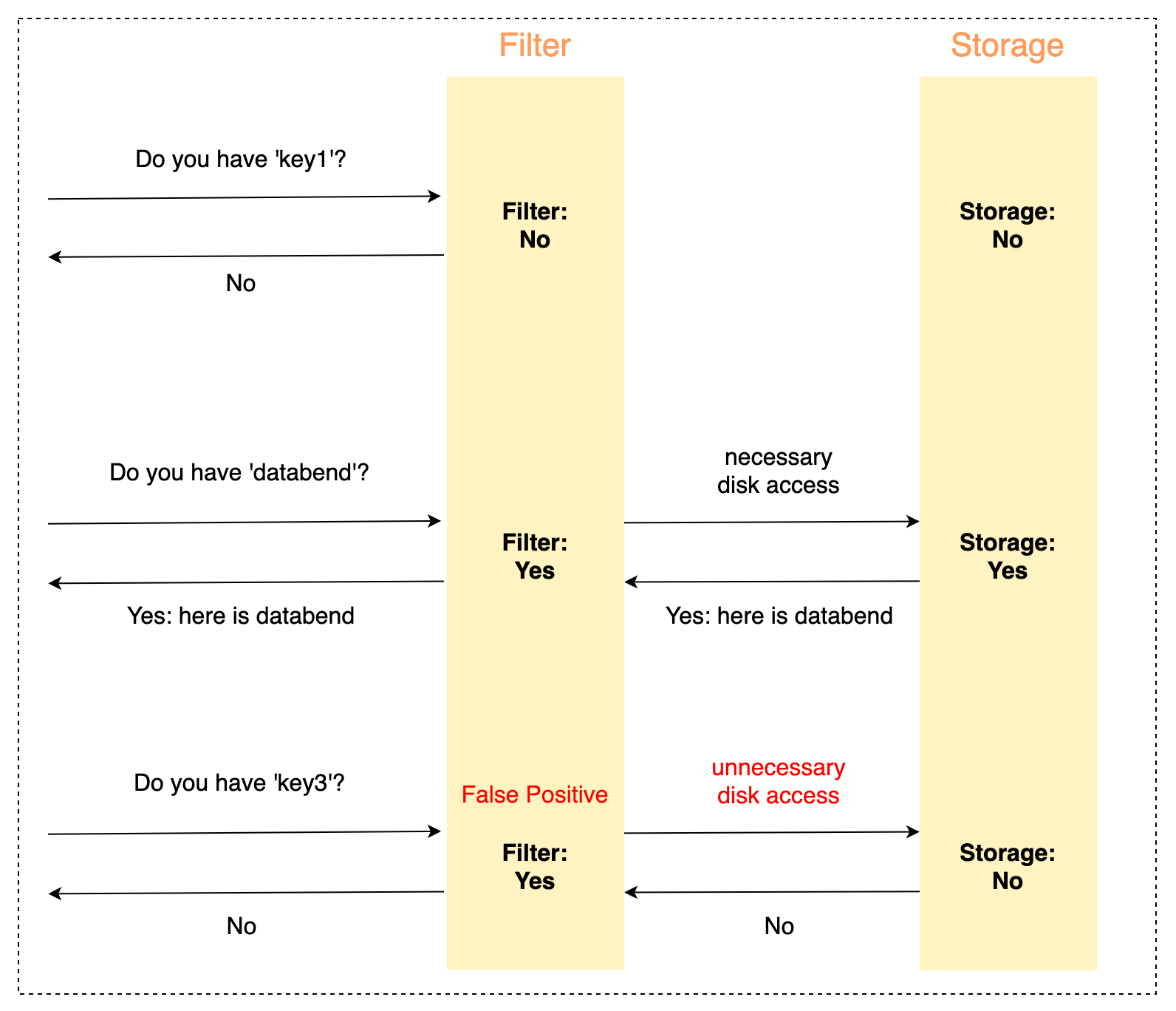
Why We Replaced the Bloom Filter
Most popular databases use Bloom Filters to handle equivalent queries and avoid useless data readings. Databend also used the classic Bloom Filter algorithm in the first version (databend#6639). However, we found the Bloom Filter Index required plenty of storage space which even exceeded the data storage size (Databend automatically created Bloom indexes for some data types to make it easier for users to work with). The Bloom Filter Index didn't show a significant performance improvement because it is not much different from reading data directly from storage.
The reason is that Bloom Filter does not know the cardinality of the data when it is generated. Take the Boolean type as an example, the algorithm allocates space for it without considering the cardinality (2, True or False).
As a result, the Databend community began exploring new solutions and determined a feasible solution that uses HyperLoglog to sort out distinct values before allocating space.
At the TiDB User Conference on a Saturday in September, I met XP (@drmingdrmer) and talked about the solution again with him. He came up with using Trie to solve the problem. An excellent idea, but lots of work.
XP is a master for Trie, so I'm sure implementation would be no big deal for him. But I think some existing technologies might be able to help.

Why Xor Filter?
A few explorations later, the Xor Filter algorithm, proposed by Daniel Lemire and his team in 2019: [Xor Filters: Faster and Smaller Than Bloom Filters, caught my attention(https://lemire.me/blog/2019/12/19/xor-filters-faster-and-smaller-than-bloom-filters/).
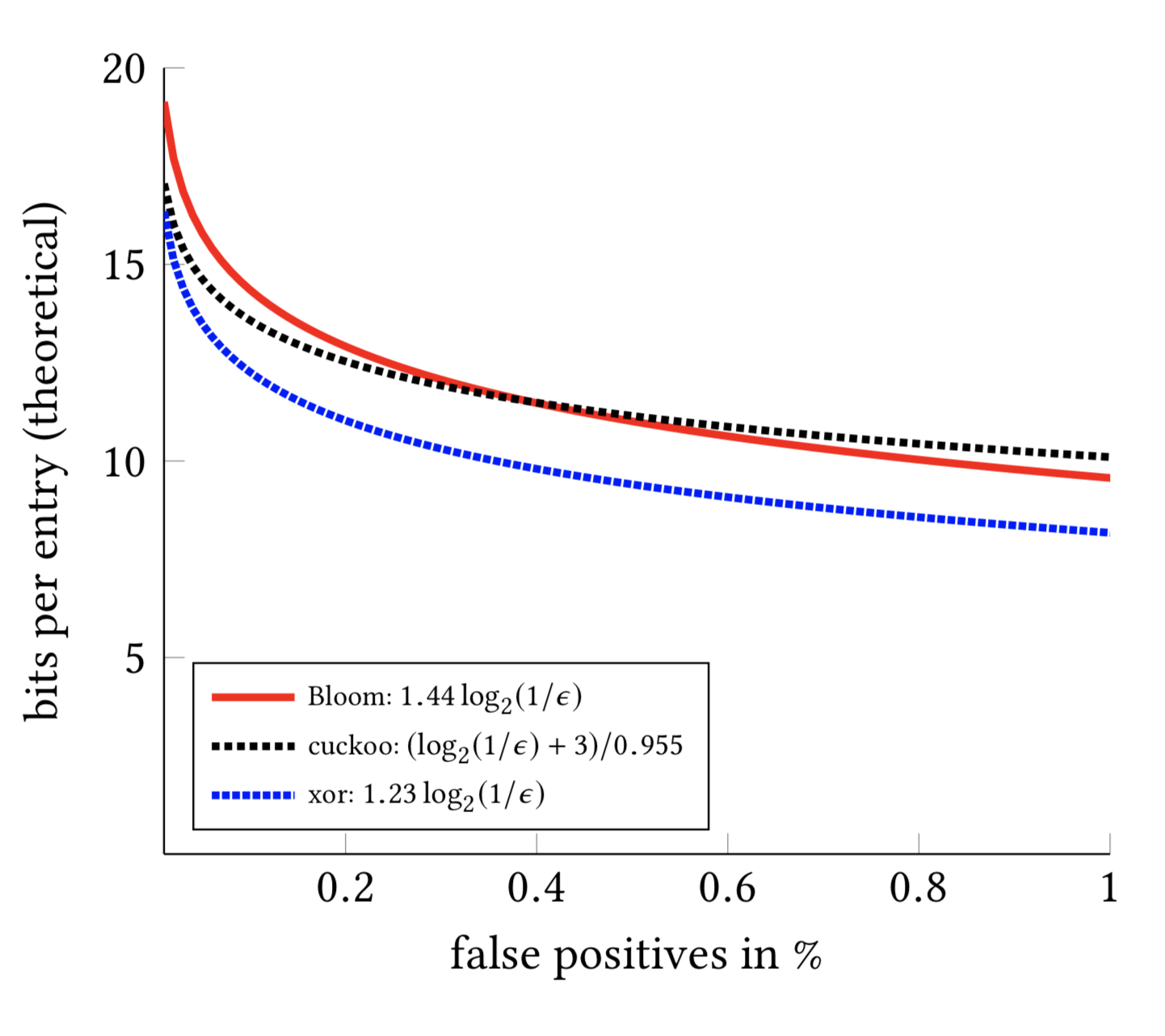
I did a test (Xor Filter Bench) with the Rust version (xorfilter) and got a very positive result, so we replaced Bloom Filters with Xor Filters by databend#7860. Let's do a test and see how it performs with Xor Filters.
u64:
xor bitmap encode:1230069 bytes, raw:8000000 bytes, ratio:0.15375863
bool:
xor bitmap encode:61 bytes, raw:1000000 bytes, ratio:0.000061
string:
xor bitmap encode:123067 bytes, raw:3000000 bytes, ratio:0.041022334
100000 records of the same key:
xor bitmap encode: 61 bytes, raw:3000000 bytes, ratio:0.000020333333
Test Environment
Databend: v0.8.122-nightly, single node
VM: 32 vCPU, 32 GiB (Cloud VM)
Object Storage: S3
Dataset: 10 billion records, 350G Raw Data, Xor Filter Index 700MB, all indexes and data are stored in object storage.
Table:
mysql> desc t10b;
+-------+-----------------+------+---------+-------+
| Field | Type | Null | Default | Extra |
+-------+-----------------+------+---------+-------+
| c1 | BIGINT UNSIGNED | NO | 0 | |
| c2 | VARCHAR | NO | | |
+-------+-----------------+------+---------+-------+
Deploying Databend
Step 1: Download installation package
wget https://github.com/datafuselabs/databend/releases/download/v0.8.122-nightly/databend-v0.8.122-nightly-x86_64-unknown-linux-musl.tar.gz
tar zxvf databend-v0.8.122-nightly-x86_64-unknown-linux-musl.tar.gz
You can find the following content after extracting the package:
tree
.
├── bin
│ ├── databend-meta
│ ├── databend-metabench
│ ├── databend-metactl
│ └── databend-query
├── configs
│ ├── databend-meta.toml
│ └── databend-query.toml
├── readme.txt
└── scripts
├── start.sh
└── stop.sh
Step 2: Start Databend Meta
./bin/databend-meta -c configs/databend-meta.toml
Step 3:Configure Databend Query
For more information, refer to https://databend.rs/doc/deploy/deploying-databend
vim configs/databend-query.toml
... ...
[meta]
endpoints = ["127.0.0.1:9191"]
username = "root"
password = "root"
client_timeout_in_second = 60
auto_sync_interval = 60
# Storage config.
[storage]
# fs | s3 | azblob | obs
type = "s3"
# To use S3-compatible object storage, uncomment this block and set your values.
[storage.s3]
bucket = "<your-bucket-name>"
endpoint_url = "<your-s3-endpoint>"
access_key_id = "<your-key>"
secret_access_key = "<your-access-key>"
Step 4: Start Databend Query
./bin/databend-query -c configs/databend-query.toml
Step 5: Construct the test data set
mysql -uroot -h127.0.0.1 -P3307
Construct 10 billion rows of test data (time: 16 min 0.41 sec):
create table t10b as select number as c1, cast(rand() as string) as c2 from numbers(10000000000)
Run a query (no cache, all data and indexes are in object storage):
mysql> select * from t10b where c2='0.6622377673133426';
+-----------+--------------------+
| c1 | c2 |
+-----------+--------------------+
| 937500090 | 0.6622377673133426 |
+-----------+--------------------+
1 row in set (20.57 sec)
Read 40000000 rows, 1009.75 MiB in 20.567 sec., 1.94 million rows/sec., 49.10 MiB/sec.
With the Xor Filter Index, it takes about 20 seconds for a single-node Databend to complete a point query on a scale of 10 billion rows. You can also speed up point queries by expanding a single Databend node into a cluster. Refer to https://databend.rs/doc/deploy/expanding-to-a-databend-cluster#deploying-a-new-query-node for details.
References
[1] Arxiv: Xor Filters: Faster and Smaller Than Bloom and Cuckoo Filters
[2] Daniel Lemire’s blog: Xor Filters: Faster and Smaller Than Bloom Filters
[3] Databend, Cloud Lakehouse: https://github.com/datafuselabs/databend